End-to-End Multi-Task Policy Learning from NMPC for Quadruped Locomotionhttps://www.hrl.uni-bonn.de/api/publications/2025/sajja2025multi-taskhttps://www.hrl.uni-bonn.de/api/publications/2025/sajja2025multi-task/@@images/image-1200-021be56d6d85b3af2f4e1e2fdd72c4d0.png
End-to-End Multi-Task Policy Learning from NMPC for Quadruped Locomotion
Publication Authors
A. Sajja;
S. Khorshidi;
S. Houben;
M. Bennewitz
Published in
Accepted to: European Conference on Mobile Robots (ECMR 2025)
Year of Publication
2025
Abstract
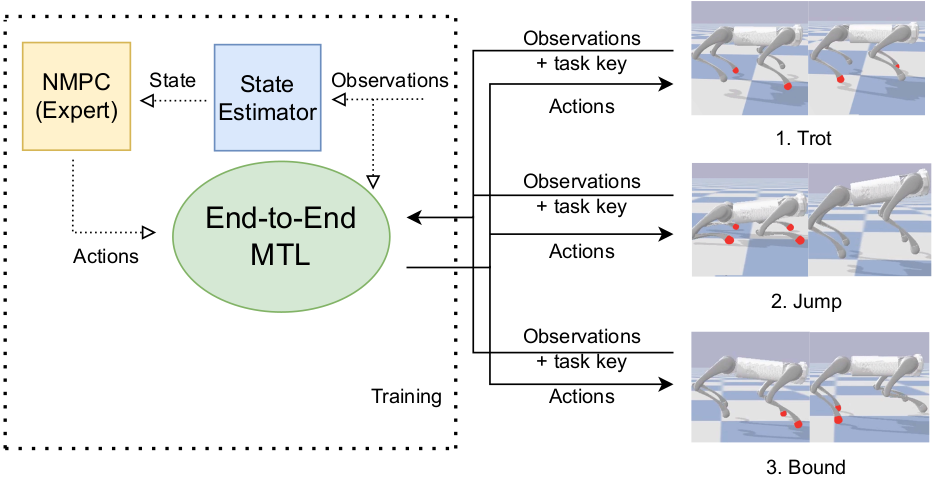
Quadruped robots excel in traversing complex, unstructured environments where wheeled robots often fail. However, enabling efficient and adaptable locomotion remains challenging due to the quadrupeds' nonlinear dynamics, high degrees of freedom, and the computational demands of real-time control. Optimization-based controllers, such as Nonlinear Model Predictive Control (NMPC), have shown strong performance, but their reliance on accurate state estimation and high computational overhead makes deployment in real-world settings challenging. In this work, we present a Multi-Task Learning (MTL) framework in which expert NMPC demonstrations are used to train a single neural network to predict actions for multiple locomotion behaviors directly from raw proprioceptive sensor inputs. We evaluate our approach extensively on the quadruped robot Go1, both in simulation and on real hardware, demonstrating that it accurately reproduces expert behavior, allows smooth gait switching, and simplifies the control pipeline for real-time deployment. Our MTL architecture enables learning diverse gaits within a unified policy, achieving high R^2 scores for predicted joint targets across all tasks.